Эта статья — солянка, собранная из доков по Python, уроков по нему же и собственного опыта. Если вам хоть раз было нужно сохранять, изменять и управлять какими-то данными в процессе геймплея, но вы не очень знали, как, она может вам пригодиться.
Говорить мы будем по факту больше о Python, потому что для данной конкретной темы это, считай, одно и то же. Если не верите, посмотрите на толстого желтого питона на аватарке Эйлин.
Кому удобнее:
эта же статья, только в гуглодоках.
 Одна из множества ошибок, связанных с типами данных.
Одна из множества ошибок, связанных с типами данных. Типы данных — это формы, в которых может храниться информация. Например, 10 — это объект числового типа данных, а вот "10" и "десять" — это уже объект строкового типа данных. Как, скажем, огурец — это объект типа "овощ", а стол — это объект типа "мебель".
Переменные — это контейнеры для информации. У каждой переменной есть
имя, по которому мы будем получать ее
значение. Чтобы создать переменную в Ren'Py, ее не нужно как-то специфически объявлять, переменная создается в момент первого присваивания ей какого-то значения. До первого присваивания она не существует, а все попытки прочитать значение несуществующей переменной вызовут ошибку.
Python — язык с динамической типизацией. Это значит, что за переменной не закрепляется раз и навсегда определенный тип данных. Физически переменная в питоне — это не набор данных, это
указатель на набор, хранящийся где-то в памяти, поэтому в одну и ту же переменную по ходу программы мы можем класть то числа, то строки, то списки. (Хотя, строго говоря, таким лучше не баловаться без нужды.)
Динамическая типизация наглядно: если вы посадили в коробку (
переменную) объект типа "кот" (
значение), то данная конкретная коробка не становится "коробкой для хранения котов". Можно вытряхнуть кота и насыпать в нее кило картохи, и ничего не случится.
Создание переменных. Чтобы создать переменную с каким-то значением заранее, в Ren'Py существуют операторы
default и
define.
Оператор define Отрабатывает в момент инициализации программы и присваивает переменной значение. Самый распространенный пример — объявление персонажей:
Код
define e = Character("Eileen")
Переменной e в момент инициализации присвоили значение — объект типа "персонаж". Эквивалентно записи:
Код
init python:
e = Character("Eileen")
Переменные, заданные таким образом, воспринимаются как
константы. Они не должны быть изменены в ходе программы и не учитываются при сохранении и загрузке. (Физически изменение не запрещено, но результат может быть непредсказуем, в том числе потому что
define всегда отрабатывает при старте/загрузке, присваивая переменной заданное значение, что бы внутри нее ни лежало до этого.)
Оператор default Отрабатывает в момент начала новой игры или загрузки сохраненной, создает переменную и присваивает ей значение, ЕСЛИ переменная до этого не существовала. Иными словами, задает значение "по умолчанию". Если переменная с таким именем уже существует на момент выполнения оператора, ничего не произойдет.
Если переменная
points не определена на этапе начала новой игры, эквивалентно записи:
Код
label start:
$ points = 0
Если переменная
points не определена на этапе загрузки сохранения, эквивалентно записи:
Код
label after_load:
$ points = 0
Поскольку
default и
define (а) операторы Ren'Py и
(б) отрабатывают на старте программы, их можно использовать в любом месте ренпи-кода. Вообще в любом, хоть посреди скрипта, проверено, работает. Но все-таки удобнее и аккуратнее делать это в начале файла/перед меткой, скинув все необходимые на данном этапе переменные в одну кучу.
Если не с помощью
define или
default, то еще операцию присваивания можно выполнить просто в любом нужном месте кода.
Код
<имя переменной> = <значение>
(это
python-код, поэтому его нужно либо помещать в
python-блок, либо экранировать строку значком
$)
Код
hero "А теперь — главный вопрос жизни, вселенной и вообще!"
$ main_question = 42
Переменные можно удалять с помощью оператора
del. При этом переменная перестает существовать и ведет себя так, как будто мы ее никогда не объявляли.
Поскольку в питоне переменная — это указатель, а не объект, то и удаляем мы указатель. Сам объект, на который ссылалась переменная, после удаления может остаться в памяти, если на него ссылается кто-то еще.
Оператор
del отвязывает имя-указатель от объекта и уменьшает
счетчик ссылок на объект на единицу. Тот же результат достигается операцией переприсваивания
None.
Код
del myvar
myvar = None
В первом случае мы напрямую отвязали указатель, во втором — перенаправили его так, чтобы он указывал на объект
None, то есть на
ничего. Счетчик ссылок на объект уменьшается в обоих случаях, однако, удалив переменную, мы больше не можем использовать ее до нового присваивания, а присвоив
None — можем этот
None оттуда прочитать.
Код
$ one = "Раз!"
"[one]" # выведет "Раз!"
$ one = None
"[one]" # Выведет None
$ del one
"[one]" # выбьет KeyError, потому что переменной one больше нет
Когда счетчик ссылок на объект становится равным нулю, память, занятая объектом, освобождается.
 Принцип работы счетчика ссылок на объект
Принцип работы счетчика ссылок на объект Можно! Не обязательно класть каждый объект в свой отдельный контейнер, чтобы выполнять над ними какие-то операции. Например, если вам нужно быстро посчитать количество символов в строке "Привет, мир!", которая больше нигде не используется, можно не писать:
Код
mystr = "Привет, мир!"
length = len(mystr)
достаточно просто:
Код
length = len("Привет, мир!")
Как можно догадаться из названия, преобразование типов — это приведение данных одного типа к другому типу. Например, превращение целого числа 10 в строку "10". или целого числа 10 в дробное число 10.0.
Зачем оно нужно? В том числе затем, чтобы складывать строку и число. Без преобразования типов это делать нельзя, как нельзя прибавить стол к огурцу или делить на ноль: не существует единственно возможного результата этого действия. Если мы складываем 10 и "10", что мы хотим получить, 20 или "1010"? Питон не знает и предпочитает не решать за нас.
Преобразование типов бывает явное и неявное. Неявное происходит без нашего вмешательства, и не приветствуется кодексом чести Настоящих Питонистов. С неявным преобразованием мы бы могли беззаботно складывать строки, числа и огурцы, не задумываясь о последствиях.
Явное преобразование выполняется вручную, и для этого предусмотрена целая куча коротких, простых и нужных функций. С большой вероятностью, вам понадобятся три:
-
str(<значение>) — преобразует <значение> в строку
-
int(<значение>) — преобразует <значение> в целое число (отбрасывает десятичную часть, а не округляет!)
-
float(<значение>) — преобразует <значение> в дробное число
Как это работает:
Код
$ ivar = int(10.7) # внутри ivar будет целое число 10
$ sum1 = float("10") + 0.1 # внутри sum1 будет 10.1
$ sum2 = float("10") + 1 # внутри sum2 будет 11.0
(В последней операции сложения целочисленная единица была неявно приведена к дробному 1.0. Но поскольку оба типа данных — числовые, и результат очевиден, это допустимо.)
Где это может пригодиться? Во-первых, в качестве результата многих операций Ren'Py возвращает строку там, где вам может понадобиться число. Возьмем, к примеру, пользовательский ввод: когда вы просите ввести имя героя, то все нормально, имя и должно быть строкой. А что, если вам хочется, чтобы пользователь ввел возраст героя? А потом к этому возрасту прибавлять и отнимать что-то еще?
Код
$ age = renpy.input("Сколько тебе лет?")
$ age_next = int(age) + 7
"Хм... тебе сейчас [age], значит, через 7 лет тебе будет [age_next]!"
Ввод с клавиатуры возвращает строковое значение, поэтому в age в момент присваивания поместили строку. Без явного преобразования ее к целому числу, операция сложения выбила бы ошибку.
Во-вторых, в питоне версий 2.х операцией деления двух целых чисел тоже будет целое число, с отброшенной дробной частью. Если нам хочется получить дробное число, то либо делитель, либо делимое (либо оба!) нужно явно преобразовать к дробному.
Код
$ idiv = 5 / 2
$ fdiv = 5 / float(2)
"Операция деления 5 на 2 без преобразования типов: [idiv]. С преобразованием типов: [fdiv]"
Теперь можно поговорить подробнее о конкретных типах данных.
None
None — это одновременно ключевое слово, значение и объект типа
NoneType. А еще это ничего. В буквальном смысле. Есть ноль, есть "ложно", а есть "ничего", которое ничего не делает и не имеет поведения.
Зачем? Чаще всего
None используется в роли флага для обозначения нейтрального значения. При написании несложного кода вряд ли
None будет выгоднее, чем
False, но в Ren'Py, особенно там, где дело касается кастомизации стилей, это слово будет часто встречаться.
Код
frame:
background None
Если вам понадобится проверить, содержит ли переменная значение
None (а не ноль и не
False), грамотнее всего будет использовать конструкцию:
Код
if my_var is None:
# внутри my_var лежит None
Конструкция:
Код
if my_var == None:
# внутри my_var лежит None
- допустима и будет работать с простыми типами данных, но не очень желательна, если внутри
my_var лежат объекты пользовательских классов.
Присваивание переменной
None происходит как обычно.
Обратите внимание, что, как
True и
False,
None пишется без кавычек и с большой буквы. Т.е. это резервированное слово, а не строка.
Логический (булев) тип. True/False
Объекты логического типа могут принимать только два значения:
True (истина) и
False (ложь). Эти значения мы можем класть в переменные.
Зачем? Логический тип данных — основа основ. Переменные со значением
True/False чаще всего используются в роли индикаторов и флагов. Но важнее то, что любой оператор ветвления
if/else работает как раз на базе
истинных и
ложных утверждений.
Любое выражение в
if <выражение> проходит проверку истинности. (Эта же проверка истинности лежит в основе явного преобразования
bool().)
Если проверять на истинность значения других типов данных, то:
- всегда ложны:
None и
False. Всегда истинный —
True;
- для
числовых типов: любой ноль (0, 0.0, любая другая форма записи) ложен, любое не равное нулю число (включая отрицательные и дробные) истинно;
- для
строковых типов: любая пустая строка ложна, строка, содержащая хотя бы один символ (в том числе, пробел) — истинна;
- для
списков, словарей и
кортежей: любая пустая структура данных ложна, если в структуре есть хотя бы один элемент (даже если этот элемент —
False) — истинна.
Код для наглядной демонстрации:
Код
$ flist = []
$ tlist = [ None ]
if flist:
"Пустой список [[ ] возвращает истину"
else:
"Пустой список [[ ] возвращает ложь"
if tlist:
"Cписок [[ None ] возвращает истину"
else:
"Cписок [[ None ] возвращает ложь"
$ fstr = ""
$ tstr = "0"
if fstr:
"Пустая строка \"\" возвращает истину"
else:
"Пустая строка \"\" возвращает ложь"
if tstr:
"Cтрока с символом, который вернет ложь: \"0\", возвращает истину"
else:
"Cтрока с символом, который вернет ложь: \"0\", возвращает ложь"
Числовые типы. Целые числа, дробные числа.
В рамках необходимого минимума я даже не знаю, что сказать про числовые типы, кроме того, что с ними можно делать все, что обычно делают с числами.
Зачем? Куча причин для того, чтобы хранить числа. Флаги этапов текущих рутов, атрибуты героя в боевой системе, отношение персонажей, идентификаторы объектов... Числа — универсальная штука. Почти как строки.
Строковый тип данных. Много букв.
Первое правило бойцовского клуба: нумерация символов в строке и элементов в списке и кортеже начинается
с нуля.
Обычная строка выглядит так:
Код
$ xstr = "Привет, мир! ' Внутри меня есть неэкранированные апострофы."
или так:
Код
$ ystr = 'Привет, мир! " Внутри меня есть неэкранированные кавычки.'
или так:
Код
$ zstr = '''Привет, мир!
Я состою из нескольких строк!
Идеально для тех, кому лень ставить экранированный перенос!'''
(тройные кавычки тоже можно).
Записи строки в апострофах и кавычках эквивалентны. Строка в тройных кавычках позволяет переносить строку обычным образом, вместо того, чтобы добавлять спецсимвол
\n в местах, где необходим разрыв строки.
В Ren'Py есть набор служебных символов, которые компилятор считает частью определенной команды. Например, открывающая фигурная скобка внутри строки — это прежде всего сигнал "здесь начинается текстовый тэг", и только потом — абстрактная закорючка на экране. В определенных случаях, чтобы отобразить такие символы внутри строки, их необходимо экранировать.
- кавычки внутри строк в кавычках и апострофы внутри строк в апострофах. Экранируются обратным слэшем:
\" и
\' - открывающая фигурная скобка. Компилятор интерпретирует ее в первую очередь как символ открывающегося текстового тэга, а уже потом — как текстовый символ. Чтобы вывести ее в виде текста, необходимо экранировать ее, задублировав:
{{ - открывающая квадратная скобка. В определенных случаях компилятор интерпретирует ее как сигнал о том, что в строку добавляется содержимое переменной. Экранируется дублированием:
[[ - обратный слэш, служебный символ для экранирования других символов. При необходимости экранируется дублированием:
\\ - значок процента. Вспомогательный символ для форматированного вывода строк, при необходимости экранируется дублированием:
%% Код
"Сейчас я покажу вам, как сказать \"привет, мир!\", не потеряв кавычки."
"Чтобы вывести значение переменной в реплике персонажа, вам понадобятся [[квадратные скобки]."
"Для стилизации текста в репликах нужны {{текстовые теги}."
"И еще пример со \\ слэшем и %% процентами."
Но это все такое, эта информация, в общем-то, есть в доках, я просто напоминаю. А вот чего в доках нет, так это подробного описания, как форматировать строки (логично, потому что это уже Python, а не Ren'Py).
"У меня есть строка, я хочу вставить в нее значение некоторой переменной". Допустим, у нас есть обычный супергерой визуальной новеллы. Как водится, его переводят в новую школу для супергероев-мутантов, и в первый же день ему нужно выйти к доске, представиться и рассказать о себе.
Код
"Привет! Меня зовут X, мне Y лет, и я умею Z!"
Представим, что X, Y и Z должен выбрать игрок. Хочет ли он, чтобы его супергерой Синдзи шестнадцати лет умел летать, читать мысли, жечь напалмом или доводить женщин до оргазма пальцем — это его дело, наше — вставить считанную и сохраненную в переменных информацию в строку.
Допустим, нужные данные уже хранятся в переменных
name, age и
ability соответственно. Первый и самый простой способ форматирования — если нам нужно просто вывести заполненный шаблон в Ren'Py-диалог:
Код
hero "Привет! Меня зовут [name], мне [age] лет, и я умею [ability]!"
Имена переменных берутся в квадратные скобки, ставятся на нужные места, и все.
Но что, если нам нужно вывести параметризованную строку не в диалог, а на экран (screen)? Или сохранить заполненный шаблон внутри какой-то переменной? Это Ren'Py умеет вынимать значения, если ему показать квадратные скобки, а с питоном нужно иначе!
Можно воспользоваться двумя способами: условно-старый — форматирование с помощью оператора
%, и условно-новый — с помощью функции
format(). Функция
format() отсутствует в старых версиях питона, а
%, говорят, уберут в новых, но ренпи стоит на стыке поколений и умеет и в то. и в другое, так что выбирайте по вкусу.
Итак, допустим, у нас есть строка, назовем ее
template, в определенные места которой нужно вставить некоторые, заранее не известные, значения:
Код
"Меня зовут <имя>, мне <возраст> лет, и я умею <скилл>!"
На примере нашей строки, общий вид оператора выглядит так:
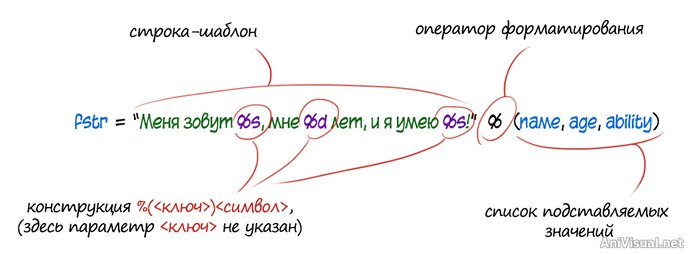
Конструкция
%<(ключ)><символ> резервирует место внутри строки. Читается как "это место занято, сейчас я принесу набор значений, достанешь из набора значение типа
<символ>, помеченное ключом
<ключ> и поставишь сюда".
<ключ> — необязательный параметр, его можно опустить,
<символ> — обязательный.
- "s" говорит "жди на этом месте строку";
- "d" говорит "жди на этом месте целое число";
- "c" говорит "жди на этом месте единственный символ"
Полный список можно найти в доках по питону. В теории, тип каждого передаваемого значения должен соответствовать типу, указанному при резервировании места. На практике можно лепить везде
%s и передавать при этом что попало, если вам не нужно углубленное форматирование значений (знаки после запятой, и т.д.) По сути, значение, ожидаемое в
%s, автоматически приводится к строковому типу и с ним будут обращаться, как со строкой.
Оператор форматирования
% после строки — отделяет строку-шаблон от списка подставляемых значений.
Вид
списка значений зависит от того, были ли в шаблоне указаны
<ключи>.
Если нет, значения передаются в скобках через запятую, в виде кортежа, строго в том порядке, в котором они должны помещаться в строку. Зарезервированных мест должно быть ровно столько, сколько передано значений (и наоборот).
Если значение только одно, скобки можно опустить.
Если же для
каждого зарезервированного места был указан ключ, то можно передать в качестве списка значений словарь с соответствующими ключами, и внутри словаря порядок пар
ключ: значение не важен.
При использовании ключей и словаря, количество зарезервированных мест может не совпадать с количеством переданных значений, но каждый ключ в строке должен иметь пару внутри словаря.
Код
# кортеж, без ключей
$ strtmp = "Привет! Меня зовут %s, мне %s лет, и я умею %s!" % (name, age, ability)
hero "[strtmp]"
# словарь, с ключами
$ strtmp = "Привет! Меня зовут %(name)s, мне %(age)s лет, и я умею %(ab)s!" % { "name": name, "age": age, "ab": ability }
hero "[strtmp]"
# словарь, повторяющиеся ключи
$ strtmp = "Привет! Меня зовут %(name)s и я умею %(ab)s! Да, вы не ослышались, я умею %(ab)s!" % { "name": name, "age": age, "ab": ability }
hero "[strtmp]"
Общая идея такая же, как для оператора %: вначале формируется строка-шаблон, потом в нее укладываются переданные значения. Синтаксис различается:
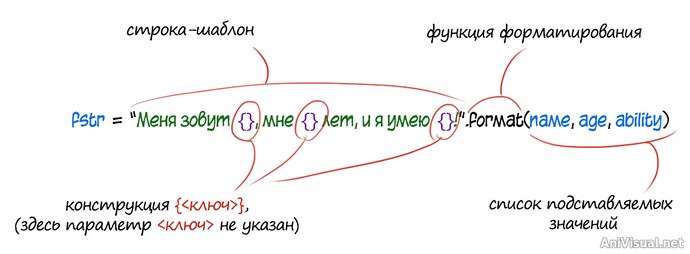
Конструкция
{<ключ>} резервирует место внутри строки, читается и работает аналогично конструкции оператора %.
<ключ> можно не указывать, можно указывать в виде идентификатора (ключа в словаре), или в виде индекса элемента (числа) в массиве передаваемых значений.
Нельзя смешивать в одном шаблоне виды ключей: либо не указываем для всех позиций, либо указываем для каждой в виде индексов, либо для каждой в виде идентификаторов.
Функция
.format() вызывается от строки-шаблона. В качестве аргументов ей передается список значений.
Вид
списка значений зависит от ключей в строке-шаблоне.
Если ключи не указаны, или указаны в виде числовых индексов, значения/переменные перечисляются в скобках через запятую.
Если указаны ключи-идентификаторы, можно передать словарь с ключами в виде
**словарь, или пары вида
ключ = значение через запятую.
Если использовать ключи, одно значение можно вставлять в строку несколько раз (как и в операторе %).
Код
# ключи не указаны
$ strtmp = "Привет! Меня зовут {}, мне {} лет, и я умею {}!".format(name, age, ability)
hero "[strtmp]"
# указание ключей в виде индексов
$ strtmp = "Привет! Меня зовут {0}, мне {1} лет, и я умею {2}! Я очень хорошо умею {2}!".format(name, age, ability)
hero "[strtmp]"
# указание ключей в виде идентификаторов: **словарь
$ strtmp = "Привет! Меня зовут {name}, мне {age} лет, и я умею {ab}!".format(**{ "name": name, "age": age, "ab": ability })
hero "[strtmp]"
# указание ключей в виде идентификаторов: пары ключ = значение
$ strtmp = "Привет! Меня зовут {name}, мне {age} лет, и я умею {ab}!".format(name = name, age = age, ab = ability)
hero "[strtmp]"
Строки можно
складывать простой операцией сложения (помните про преобразование типов, все слагаемые должны быть строковыми значениями):
Код
$ str1 = "Привет"
$ str2 = "мир!"
$ str3 = str1 + ", " + str2
"[str3]" # выведет строку "Привет, мир!"
строку на число N, можно продублировать строку N раз:
Код
$ very = "очень"
$ lotsof = very * 5
"Синдзи, твоя тян тебя [lotsof] любит!"
# выведет строку "Синдзи, твоя тян тебя оченьоченьоченьоченьочень любит!"
Функции
смены регистра:
-
string.upper() — переводит все символы строки
string в верхний регистр
-
string.lower() — переводит все символы строки
string в нижний регистр
-
string.capitalize() — переводит первый символ строки
string в верхний регистр, остальные символы — в нижний
-
string.title() — переводит первый символ каждого слова строки
string в верхний регистр, остальные — в нижний
-
string.swapcase() — меняет регистр всех символов строки
string на противоположный
Эти функции возвращают новую строку, которую нужно либо закинуть в переменную, либо сразу использовать в выражении. Оригинальная строка
string при этом
не меняется.
Код
# вызывать функции можно как от голых строк, так и от переменных, содержащих строки:
$ loud = "Это чтобы лучше было слышно".upper()
$ ask = "ПОЖАЛУЙСТА, ХВАТИТ ОРАТЬ!"
$ ask_quietly = ask.lower()
$ deutsch = "а Я пИшУ кАк нЕмЕц.".title()
"[loud] — [ask_quietly]"
# выведет: "ЭТО ЧТОБЫ ЛУЧШЕ БЫЛО СЛЫШНО — пожалуйста, хватит орать!"
"[deutsch]"
# выведет: "А Я Пишу Как Немец."
С помощью функции
len() можно посчитать длину строки. Она принимает в качестве аргумента строку, длину которой нужно найти, и возвращает количество символов в этой строке в виде целого числа. Это значение нужно либо закинуть в переменную, либо сразу использовать в выражении.
Код
$ lstr = len("Строка длиной 26 символов.")
"[lstr]" # выведет "26"
Функция
replace():
string.replace(template, change) позволяет заменить вхождения подстроки
template в строку
string строкой
change. Она возвращает новую строку, которую нужно либо закинуть в переменную, либо сразу использовать в выражении. Оригинальная строка
string при этом не меняется.
Код
$ rstr = "Я буду звать тебя Синдзи, Синдзи!".replace("Синдзи", "Сёма")
"[rstr]" # выведет: "Я буду звать тебя Сёма, Сёма!"
Функция
split() позволяет разбить строку на набор элементов. Вызов
string.split(divider) возвращает список кусочков строки
string, разделенной в местах вхождения разделителя
divider. Сам разделитель в кусочки не включается.
Код
$ ostr = "Строка, которую будем разбивать."
$ lst = ostr.split(" ")
# внутри переменной lst будет лежать список: [ "Строка,", "которую", "будем", "разбивать." ]
Функция
join() позволяет собрать строку на основе списка элементов и элемента-склейки. Вызов
divider.join(list) вернет строку, склеенную из элементов списка
list, между которыми будет проложена строка
divider. Аналогично, результат нужно либо закинуть в переменную, либо сразу же использовать в выражении, ни массив, ни строка-склейка изменены не будут.
Код
$ ostr = "Cтрока, которую будем разбивать."
$ lst = ostr.split(" ")
$ nstr = "_".join(lst)
"[nstr]" # выведет: "Cтрока,_которую_будем_разбивать."
С помощью
find() и
rfind() можно найти индекс первого/последнего вхождения подстроки в строку. Вызов
string.find(substring) возвращает индекс первого вхождения строки
substring в строку
string, или -1, если подстроки в строке нет. Нумерация символов (индексов) начинается с нуля.
Код
$ longstring = "Эй, привет, мир! Я пришел сказать тебе привет!"
$ first = longstring.find("привет")
$ last = longstring.rfind("привет")
"Первое вхождение слова 'привет': [first]. Последнее: [last]." # 4 и 39 соответственно
Кроме этого, к отдельным областям строки можно получать
доступ по индексу:
string[index] — возвращает символ строки
string, стоящий на позиции
index. Если
index — отрицательное число, то отсчет символов идет с конца строки к началу.
string[from:to:step] — получение среза строки
string, начиная с символа
from, заканчивая символом
to (не включая его), с шагом step. Справедливо следующее:
- если
from или
to будут отрицательными, индекс будет считаться с конца строки к началу;
- по умолчанию
step в записи опускается и равен 1;
- если не указан параметр
from, то срез начинается с начала строки;
- если не указан параметр to, то срез заканчивается концом строки;
Код
$ s1 = "Первая строка"[1]
# получаем символ на позиции 1: е
$ s2 = "Вторая строка"[1:6]
# получаем срез с 1 по 6 позицию (не включительно): торая
$ s3 = "Третья строка"[1:-1]
# получаем срез с 1 позиции, считая с начала, по 1 позицию, считая с конца: ретья строк
$ s4 = "Четвертая строка"[::3]
# получаем срез с начала строки до конца, с шагом 3 (каждый символ с позицией, кратной 3, относительно начала среза): чвт ра
Разумеется, это не все доступные операции над строками — только те, которые вероятнее всего могут быть полезны среднестатистическому ВН-кодеру. В следующей части будет разобрана работа с кортежами, списками и другими составными типами данных. Спасибо, что дочитали.





Комментарии к записи: 4
Не могу понять как сделать...