Продолжение темы работы с данными. Первая часть
здесь, целиком статья (обе части)
в гуглодоках (там же есть ссылки на всякие stackoverflow, если кто захочет дополнительно почитать по теме).
Кортежи, списки, словари, множества: составные типы данных. Составные (сложные) типы данных описывают коллекции произвольных объектов. Объект-коллекция, переменная-коллекция — это набор пустых ячеек-переменных, которые подчиняются всем законам переменных. Внутри переменной-списка в соседних ячейках вперемешку могут храниться числа, строки,
True/False значения, другие списки, и это будет нормально.
Почему аж четыре (на самом деле пять, множества делятся на
sets и
frozensets) типа данных создали для описания "кучи случайных объектов вповалку"? Для выполнения разных задач.
Коллекции бывают:
-
упорядоченные (в каком порядке сложил в мешок, в таком и лежат): списки и кортежи;
-
неупорядоченные (складывай, не складывай — храниться будут вперемешку): множества и словари;
-
изменяемые (создал коллекцию, захотел изменить/удалить/добавить элемент — сделал это): списки, словари и set-множества;
-
неизменяемые (что и сколько положил при создании, с тем изволь и работать): кортежи и frozenset-множества
- хранение с доступом
по индексу (доступ к элементу в коллекции осуществляется только по его порядковому номеру в списке): кортежи и списки;
- хранение с доступом
по ключу (для доступа к элементу в коллекции нужно знать его имя-идентификатор): словари;
- хранение
без прямого доступа (есть обходные пути, но нет возможности сказать "дай мне пятый элемент набора"/"дай мне элемент с ключом Х"): множества.
Лирическое отступление: я не буду здесь раскрывать все нудные тонкости работы со сложными типами данных и перечислять абсолютно все операции над ними — только интересные штуки и то, что может пригодиться для понимания и уверенной работы в рамках создания новелл.
Списки (lists)
Если вы видите перечисление объектов через запятую внутри квадратных скобок, скорее всего, перед вами список.
Код
mylist = [ "10", "огурец", 42 ]
Создать список проще всего так, как на примере выше — присвоив переменной набор объектов, взятый в квадратные скобки. Если вы пока не знаете, что будет в списке, и собираетесь заполнять его постепенно, можно создать его пустым:
Доступ к любому элементу (ячейке) списка осуществляется по индексу — порядковому номеру. Нумерация ячеек начинается с
нуля. На примере списка выше:
Код
myvar = mylist[1]
# внутри переменной myvar будет храниться строка "огурец".
строку можно рассматривать, как список символов. Отсюда и доступ к символу внутри строки по индексу, и всякие срезы.
Обратившись к элементу списка по индексу, мы можем изменить его значение, как делаем это с обычной переменной:
Код
mylist[1] = "соленый огурец"
mylist[2] -= 1
# список изменится на: [ "10", "соленый огурец", 41 ]
Если обратиться к несуществующему индексу списка, компилятор выбьет ошибку.
Списки и цикл for Допустим, у нас есть список:
Код
lst = [ 1, 22, 333, 4444 ]
И нам нужно вывести на экран его элементы. Это можно сделать с помощью прохода по списку циклом
for:
Код
screen list():
vbox:
for item in lst:
text str(item)
В примере выше происходит следующее: цикл
for проходит по каждому из элементов списка
lst, кладет текущий рассматриваемый элемент внутрь переменной
item, приводит его значение к строковому типу и выводит в виде текста. На каждом шаге цикла внутри переменной
item хранится новое значение,
копия того, что лежит в списке
lst. Поэтому изменение переменной
item не затронет содержимое списка
lst.
Но что если нам нужно пройтись по списку, меняя значения его элементов? Для этого нужно обращаться напрямую к элементам списка по индексу. Вот так:
Код
for id in range(len(lst)):
lst[id] += 1
Что происходит здесь? Для начала мы считаем количество элементов в списке с помощью метода
len(). После чего приказываем запустить цикл от 0 до <длина списка - 1> (включительно) с помощью
range(<длина списка>). Теперь на каждом шаге цикла внутри переменной
id будет лежать число от 0 до 3 (в нашем списке
lst четыре элемента). Индекс, по которому нужно обращаться к элементам списка, тоже проходит итерацию от 0 до 3, поэтому мы можем использовать
id в качестве этого индекса.
Лирическое отступление: в Python 2.x
range() создает список,
xrange() создает итератор по списку, и
не хранит его. Поэтому для использования в цикле
for на больших массивах данных немного выгоднее
xrange().
Теперь можно два примера совместить в один и получить тестовый проект!
Код
default lst = [ 1, 2, 3, 4 ]
screen lists():
vbox:
for i in lst:
text str(i)
label start:
scene black
show screen lists
pause
"Прибавим к каждому элементу 1..."
python:
for i in range(len(lst)):
lst[i] += 1
"Возведем каждый элемент в квадрат..."
python:
for i in range(len(lst)):
lst[i] *= lst[i]
pause
Функции работы со строками создают новую, измененную строку, и не трогают оригинал. Функции работы со списками изменяют список-оригинал. Нужно это помнить.
Добавить новый элемент в список можно с помощью функции
.append():
list.append(item). Объект
item будет помещен в конец списка
list. Если нужно добавить элемент не в конец, а на позицию
index, пользуйтесь функцией
.insert():
list.insert(index, item).
Соединить два списка в один поможет
.extend():
list.extend(another_list). В конец списка
list будут по одному добавлены элементы списка
another_list, сам список
another_list останется без изменений.
Функция
.remove() — удаление элемента по его значению.
list.remove(4) удалит первую встреченную четверку из списка
list.
Функция
.pop() — удаление элемента по его индексу.
list.pop(id) удалит из списка
list элемент с индексом
id, и вернет его значение (которое можно поймать в переменную). Если
id не указан, будет удален последний элемент списка.
Метод
.index() возвращает индекс элемента по его значению.
list.index(item, start, end) — вернет порядковый номер первого встреченного в списке
list элемента со значением
item. Искать метод будет начиная с позиции
start и заканчивая позицией
end.
Start и/или
end можно не указывать, тогда поиск будет с начала списка и до его конца. Если элемента с таким значением не найдено, компилятор выбьет ошибку.
Оператор
in поможет проверить, есть ли элемент со значением
val в списке
list: Код
if val in list:
"[val] в списке."
else:
"[val] нет в списке."
Еще с помощью модуля
random можно получить случайный элемент списка
list: Код
rnd = renpy.random.choice(list)
Или
перемешать список, расставив элементы в случайном порядке:
Код
renpy.random.shuffle(list)
Кроме этого, списки можно
складывать, соединяя два списка в один:
Код
list_one = [ 1, 2, "42" ]
list_two = list_one + [ 2, 3 ]
# внутри переменной list_two будет список: [ 1, 2, "42", 2, 3 ]
new_list = [ 1, 2, 5 ] + [ 7 ]
# внутри переменной new_list будет список: [ 1, 2, 5, 7 ]
Обратите внимание: чтобы добавить единственный элемент, мы берем его в скобки, создавая одноэлементный список на лету. Потому что нельзя складывать стол и огурец, список и число. А два списка — вполне себе можно.
Еще списки можно
умножать на число, складывая N копий одного и того же списка:
Код
list = [ 0, 42 ] * 3
# внутри переменной list будет список: [ 0, 42, 0, 42, 0, 42 ]
Кроме этого, можно посчитать длину списка с помощью функции
len(), и получить срез списка, как мы делали это со строками.
Кортежи (tuples)
С кортежами все просто. Кортежи — это списки, которые нельзя изменять, и от списков они отличаются только этим. И тем, что записываются в круглых скобках. Если перед вами запись вида:
Код
mytuple = ( "суббота", "воскресенье" )
...то вы смотрите на кортеж.
В каких случаях и почему выгоднее использовать кортежи, а не списки? 1. Кортежи занимают гораздо меньше места в памяти.
2. Они защищены от случайных изменений.
3. Их можно использовать в качестве ключей для словаря!
Код
$ dict = { (0, 1): "Мой ключ — кортеж", "str": "А мой — строка" }
(но про словари мы еще поговорим)
Чаще всего в контексте Ren'Py с кортежами мы сталкиваемся при стилизации экранов. Парные позиционирующие свойства, вроде
pos, anchor, align, xysize — все они принимают значения в виде кортежей.
Код
style some_frame:
xysize (800, 600)
pos (20, 100)
Создается кортеж аналогично списку:
Код
tuple_one = () # пустой кортеж
tuple_two = (42, 0, "соленый огурец") # кортеж со значениями
tuple_three = 42, 0, "hello world" # скобки можно опускать
...за одним хитрым исключением: создавая кортеж из одного элемента, нужно поставить после него запятую, обозначив, что нам нужен
кортеж из строки/числа/значения, а не строка/число/значение.
Код
not_a_tuple = ( "нету запятой — получи строку!" )
a_tuple = ( "а теперь это кортеж из единственного элемента!", )
С кортежами можно делать все, что можно делать со списками, кроме тех действий, которые изменяют сам кортеж — порядок его элементов или их значения. Например, мы не сможем ни удалить элемент из кортежа, ни перемешать его.
Распаковка и обмен значений Иногда нужно извлечь содержимое кортежа в отдельные переменные. Вместо того, чтобы пошагово присваивать каждое значение, обращаясь к ним по индексу, можно распаковать кортеж одной строкой:
Код
v1, v2, v3 = (0, 42, "boop")
# теперь в v1 лежит 0, внутри v2 — 42, внутри v3 — строка "boop"
Кроме этого, с помощью кортежей можно аналогичным образом менять между собой значения переменных:
Код
a, b = b, a
# теперь внутри a лежит значение, которое было в b
Фактически, в записи выше мы распаковываем созданный на лету кортеж
(b, a) в пару переменных
a и
b. Скобки при создании кортежа в данном случае опускаются.
Если можно создавать кортеж, опуская скобки, то зачем их вообще писать? Правило хорошего тона. Плюс, при других действиях с кортежами не всегда разрешено опускать скобки. Так что старайтесь не забывать про них.
Словари (dictionaries)
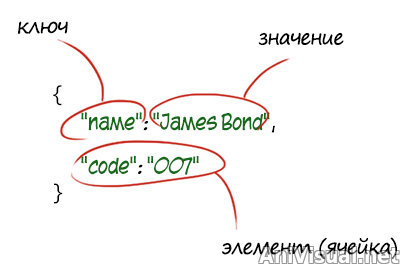
Словари — неупорядоченные изменяемые коллекции, состоящие из набора пар "ключ — значение".
Если перед вами запись вида:
Код
mydict = { "name": "James Bond", "code": "007" }
...то это наверняка словарь. Создать словарь можно как на примере выше, присвоив переменной набор пар, взятых в фигурные скобки:
Код
empty_dict = {} # пустой словарь
Можно с помощью метода
dict(), передав в качестве аргументов пары в виде "ключ = значение".
Код
mydict = dict(name = "James Bond", code = "007")
Можно с помощью того же метода
dict(), передав в качестве аргументов список кортежей из двух элементов (наверное, есть случаи, когда это удобнее всего!)
Код
mydict = dict([ ("name", "James Bond"), ("code", "007") ])
Ключи в словаре не могут повторяться. Если при создании словаря у двух или более элементов будет указан один ключ, то в словарь запишется только последняя по счету пара. Ключом может быть любой неизменяемый объект: строка, число, кортеж. Но
не переменная, внутри которой находится строка, число или кортеж, потому что переменная — это изменяемый объект. В одном словаре не запрещено смешивать ключи разных типов (строки, числа...), но это не очень хорошая практика.
Обращаться к отдельным элементам словаря нужно по их ключу:
Код
agent_code = mydict["code"] # считываем значение элемента с ключом "code" и кладем в переменную agent_code
mydict["name"] = "Top Secret" # изменяем значение элемента с ключом "name" c "James Bond" на "Top Secret"
Если попытаться считать элемент по несуществующему ключу, компилятор выбьет ошибку. Если попытаться записать что-то в элемент с несуществующим ключом, то этот ключ и соответствующее значение будут добавлены в словарь.
Код
loc = mydict["current_location"] # выбьет ошибку
mydict["current_location"] = "London" # добавит пару "current_location": "London" в словарь mydict
В примере выше мы делали это так:
Код
mydict["some_key"] # "Эй, значение по адресу some_key!"
Альтернатива — использовать методы словарей:
.get(key, default) и
.setdefault(key, default). Параметр
default в обоих методах можно не указывать. Оба метода возвращают значение по ключу
key, а если такого ключа нет, не вызывают ошибку, а возвращают
default. Если
default не указан, то метод вернет
None. Безопаснее, чем звать через квадратные скобки!
При этом метод
.get() не изменяет сам словарь, а
.setdefault(), не найдя ключа в словаре, не только вернет значение по умолчанию, но и добавит недостающую пару ключ-значение (по умолчанию) в словарь.
Код
# положит в namevar значение ключа name из mydict, если такого ключа нет, положит в namevar строку "Сёма"
namevar = mydict.get("name", "Сёма")
# положит в namevar значение ключа name из mydict, если такого ключа нет, положит в namevar строку "Сёма", и добавит в mydict ключ name со значением "Сёма"
namevar = mydict.setdefault("name", "Сёма")
Если у нас есть такой замечательный
.get(), который страхует от ошибок (на самом деле правильнее сказать исключений), то зачем нам квадратные скобки?
1. .get() медленнее. Но разница в скорости на данный момент настолько мала, что будет заметной только на больших массивах данных, с которыми вряд ли придется работать авторам ВН.
2. Иногда нужно отслеживать исключения.
.get() их игнорирует, поэтому если вам нужно не получить значение любой ценой, а отловить ошибку, обращайтесь к элементу словаря по ключу в скобках.
3. .get() делает лишнюю работу за вас. Если вам не важно, есть ключ, или нет, а нужно получить хоть какое-то значение, пускай по умолчанию, пользуйтесь методом
.get().
Субъективное мнение: обращение через индекс в скобках привычнее, универсальнее и на глаз более быстро "считывается" из кода, чем обращение по методу.
Что еще можно делать со словарями? Метод
.update(some_dict) добавляет в словарь пары ключ-значение из словаря
some_dict. Если в оригинальном словаре есть ключи, совпадающие с ключами из
some_dict, их значения перезапишутся.
Код
mydict = { "name": "Синдзи", "job": "пилот ОЧР" }
mydict.update({ "name": "Сёма", "sex": "муж" })
# словарь mydict приобретет вид: { "name": "Сёма", "sex": "муж", "job": "пилот ОЧР" }
С помощью ряда методов можно получить отдельно ключи, или отдельно значения, или все вместе.
Код
mydict = { "name": "Синдзи", "job": "пилот ОЧР" }
Метод
.keys() вернет
список всех ключей словаря.
Код
keys = mydict.keys()
# вернет [ "job", "name" ]
Метод
.values() вернет
список всех значений в словаре.
Код
values = mydict.values()
# вернет [ "пилот ОЧР", "Синдзи" ]
Метод
.items() вернет
список кортежей (ключ, значение)
Код
items = mydict.values()
# вернет [ ("job", "пилот ОЧР"), ("name", "Синдзи") ]
Чаще всего эти методы используются для прохода по элементам списка в цикле
for.
Словари и цикл for В случае со списками мы проходили по элементам так:
Но в словарях каждый элемент состоит из двух — ключа и значения! Как запустить цикл по паре? Как достать обе части?
Для начала: у словарей есть встроенный итератор, поэтому запись:
- не будет ошибкой. На каждом шаге цикла в
key будет помещаться ключ текущего элемента, после чего можно будет сделать так:
Код
for key in dict:
value = dict[key]
- и мы получим нашу пару ключ/значение. Если такой вид записи вас не устраивает, можно воспользоваться методом
.items(): Код
for key, value in dict.items():
# в key будет храниться ключ текущего элемента
# в value — значение текущего элемента
Как это работает? Справа от
in стоит запись
dict.items() — т.е. по сути список кортежей (ключ, значение). Т.е. задача сводится к итерации по списку. Т.е. на каждом шаге мы берем из списка элемент и кидаем его в то, что стоит слева от
in. Элемент списка представляет собой кортеж, а слева стоит запись вида
key, value. Помните про распаковку кортежей? Именно это и происходит.
Для наглядности, можно записать вот так:
Код
for dtuple in dict.items():
# в dtuple[0] будет ключ текущего элемента словаря
# в dtuple[1] будет значение текущего элемента словаря
Почему
for key in dict, если можно
for key in dict.keys()? В чем разница между
dict.items(), dict.viewitems() и
dict.iteritems()? Что быстрее, что правильнее, что безопаснее?
Для питона версий 2.х: 1.
for key in dict против
for key in dict.keys() На наш взгляд эти две операции выполняют одно и то же действие: проходят по массиву ключей словаря. Однако предпочтительнее пользоваться первой. Почему?
i) in dict.keys() медленнее: вместо одного действия (итерации по некоторому набору значений), сначала создается и возвращается список ключей, а уже потом по нему начинается итерация.
in dict работает на встроенном итераторе, на каждом шаге он просто выхватывает из словаря новый ключ, не зная, что будет за ним.
Кроме этого,
dict.keys() еще и более ресурсоемкий — заранее созданный список ключей отжирает место в памяти.
ii) in dict.keys() статичный: создавая список ключей для итерации, мы снимаем
копию текущего состояния словаря. Если со словарем что-то произойдет после снятия этой копии, на копии это не отразится.
Код
mydict = { "name": "Синдзи", "job": "пилот ОЧР", "code": "007" }
keys = mydict.keys()
del mydict["code"]
for k in keys:
v = mydict[k]
Код в примере выше на определенном моменте выбьет ошибку, потому что сначала мы сняли копию списка ключей, а потом удалили один элемент из словаря. Но в копии списка ключей он остался! И проходя по ней циклом, мы пытаемся найти значение по несуществующему ключу. Если запустить цикл в виде:
- то просматривать мы будем актуальный словарь и актуальные ключи, и ошибки не будет.
2.
dict.items(), dict.viewitems() и dict.iteritems() На наш взгляд, использованные в цикле
for, все эти методы делают одно и то же — предоставляют нам кортеж
(ключ, значение), с которым мы можем дальше что-то делать. Отдельно взятый код:
Код
for k, v in items:
# сделаем что-нибудь с k и v
- будет выполняться одинаково для
items, равных
dict.items(), dict.iteritems() и
dict.viewitems(). Однако вне контекста цикла
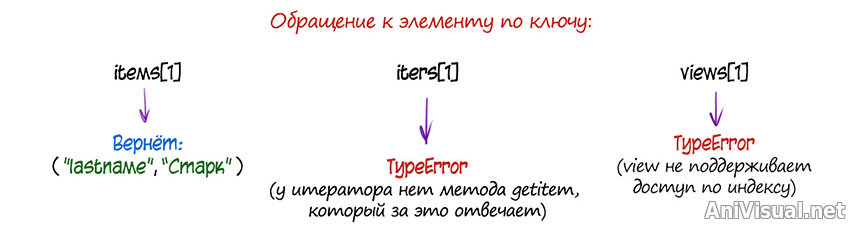
for все три метода возвращают объекты разных типов данных.
.items() возвращает список кортежей (ключ, значение), соответствующий
копии текущего состояния словаря. Все, что произойдет с оригиналом словаря после выполнения метода
.items(), на его результате не отразится (снова видим статичность). Кроме того, результат его работы — список — ресурсоемкий в сравнении с двумя другими.
.iteritems() возвращает объект типа
итератор, специальный механизм, который оценивает структуру словаря и помогает проходить по ней, выхватывая из словаря по одному элементу за раз. Он относительно статичен: значения по ключам выбирает актуальные в данный момент времени, а вот саму структуру ключей запоминает в момент создания итератора. Поэтому если сначала создать итератор словаря, а потом удалить из этого словаря элемент, использовать созданный итератор не получится.
.viewitems() возвращает специфический объект типа
view. Упрощенно: подвижное окно, в которое видно только один элемент за раз. Если изменить словарь-оригинал, его изменения отразятся и на связанном с ним
view-объекте.
Что из трех выбрать? По ситуации.
View и итераторы — не списки, из них нельзя получить значение по ключу напрямую, поэтому если вам нужно работать с данными вне цикла, лучше использовать
.items().
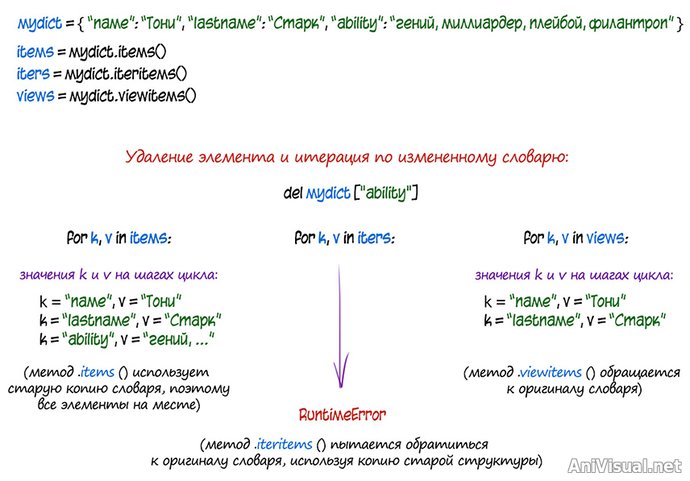


Если вам нужно просто пройти по словарю циклом, быстрее и проще будет воспользоваться итератором или view. View быстрее (на малых объемах данных разницы не видно) и гибче, но могут вызывать проблемы с совместимостью (view были введены как аналог нового механизма из версий 3.х). Использование итераторов для прохода по словарю считается более традиционным.
Для питона версий 3.х: (...в контексте Ren'Py эта информация пока что не понадобится — пока PyTom не закончит версию движка, работающую исключительно на Py3.x)
Лирическое отступление: у меня не было данных, использует ли Ren'Py в этой части движка питон 2.х, но пара тестов показали, что скорее всего использует, потому что
.items() возвращает объект типа "список" (а не
view-объект), а
.viewitems() и
.iteritems() работают как надо.
Для версий 3.x ситуация немного изменилась. За функционал метода
viewitems() теперь отвечает
.items(), а два остальных метода вычеркнуты, как устаревшие. Чтобы не путаться, вот наглядная табличка, что чем стало:
Dсе рассмотренные методы существуют в трех вариантах: items/viewitems/iteritems для пар ключ-значение, keys/viewkeys/iterkeys для ключей и values/viewvalues/itervalues для значений.
Сложные структуры: копирование. "Почему изменяются словари, которые я не редактировал?" Вот, к примеру, код:
Код
python:
a = ["1", "2", "3", "4", "5", "6"]
b = a
a[1] = "42"
tmp = " ".join(b)
"[tmp]"
Создали список
a, потом присвоили переменной
b переменную
a, изменили один элемент внутри списка
a, склеили из
b строку, вывели на экран... погодите, почему изменения из
a отразились в
b?
Потому что, напоминаю: переменные — это указатели. И на самом деле обе переменные ссылаются на один и тот же список, и модифицируя его из одной переменной, мы модифицируем его для обоих. Но что, если нам нужно два изначально
одинаковых, но
независимых списка?
Ну, мы можем написать:
Код
a = ["1", "2", "3", "4", "5", "6"]
b = ["1", "2", "3", "4", "5", "6"]
- но мало того, что это дурной тон, сложно править, так еще и неудобно, если в списках под сотню элементов — в коде лишнее место.
Поэтому нужно использовать инструмент копирования.
Есть два вида копирования: поверхностное и глубокое. При поверхностном копировании создаются
копии-указатели: каждый из наборов будет содержать
разные переменные, но ссылаться они будут на
одни и те же объекты. Если в наборе содержатся только неизменяемые объекты (строки, числа, булевы значения), то нам хватит и поверхностной копии.
А что, если внутри списка/словаря лежит изменяемый объект — другой список/словарь? Изменяя вложенный список через поверхностную копию, мы изменим и вложенный список у оригинала, и наоборот.

Чтобы этого избежать, существует глубокое копирование, которое снимает копию не указателей, а самих объектов, создавая независимый дубликат на всех уровнях вложенности.

Глубокое копирование имеет смысл только если вы работаете с наборами изменяемых объектов (набор списков, набор словарей). Копируя наборы неизменяемых объектов, можно и нужно обойтись поверхностным копированием.
Поверхностное копирование можно выполнить несколькими способами. Для списков самые быстрые и простые:
Код
# через получение среза старого массива, от начала до конца
new_list = old_list[:]
# с помощью операции добавления старого списка в конец нового (пустого)
new_list = []
new_list.extend(old_list)
# создавая новый список на базе старого с помощью функции list()
new_list = list(old_list)
Для словарей можно создать словарь на базе другого словаря или воспользоваться встроенным методом
.copy():
Код
new_dict = list(old_dict)
another_new_dict = old_dict.copy()
Глубокое копирование в версии 2.х выполняется одинаково для списков и словарей, с помощью модуля
copy, метода
.deepcopy(). Перед тем, как использовать его в коде Ren'Py, модуль нужно подключить командой
import.
Код
# включаем модуль copy
import copy
# вызываем метод deepcopy() от модуля copy, в качестве аргумента передаем старый набор, метод возвращает его копию, кладем копию в переменную new
new = copy.deepcopy(old)
Для удаления части списка или словаря, используйте оператор
del.
Код
# удаляет элемент по ключу some_key из словаря mydict
del mydict["some_key"]
# удаляет второй по счету элемент списка mylist
del mylist[1]
# удаляет весь список mylist и весь словарь mydict
del mydict
del mylist
# удаляет срез списка а, начиная с элемента с номером 1 и заканчивая элементом с номером 3 (не включая)
del mylist[1:3]
Иногда нужно не удалять набор совсем, а очистить его (превратить в пустой список или словарь соответственно). Для этого у списков и у словарей существует метод
.clear():
Код
# никаких операций присвоения не нужно, метод изменяет список/словарь, от которого его вызвали
mylist.clear() # внутри mylist теперь лежит []
mydict.clear() # внутри mydict теперь лежит {}
Потому что в питоне переменные — это не объекты, а... все верно, указатели. Если у вас есть объект-набор, на который указывает несколько переменных, то операция вида:
- создаст новый объект (пустой набор) и перенаправит на него только один указатель. Если нужно очистить
объект, т.е. чтобы все указывающие на него переменные стали указывать на пустой набор, пользуйтесь методом
.clear().
 В заключение или Зачем все это было.
В заключение или Зачем все это было. В статьях про возможности Ren'Py хочется рассказывать об интересных и непривычных вещах, методах и хитростях. Уходить куда-то за границы просто диалоговых реплик, вывода картинок и меню. И там, в этом где-то, постоянно придется сталкиваться с переменными, типами данных, словарями и форматированием строк, и было бы нечестно рассчитывать на то, что здесь каждый первый — программист, и знаком с этими вещами.
Этими статьями я пытаюсь подвести базу, чтобы в будущем ваш взгляд не спотыкался о конструкции типа
"button_%s.png", или
for k, v in dict.items(), чтобы вы не путали
default и
define и понимали, что когда используется. И чтобы ничего не мешало вникать в то, что делает тот или иной код.
А следующая часть будет про функции, экранные экшены и curried-функции. Спасибо, что дочитали.






Комментарии к записи: 6
Дочитал до момента про списки и расстроился. Хорошо же ведь начиналось...
На заметочку - нужно мыслить вариативно, а не так, как навязывают нам разработчики всяких "движков". Если Ренпай на Питоне, то мыслить нужно как программист на Питоне... Потому как вот мне, программисту, без примеров кода вообще непонятно, что, зачем и куда. Смысл статьи - абстракция, типизация полиморфизм данных. И половину поста можно смело выбросить.
И какие нахрен списки? Какие кортежи? Какие распаковки и обмены значениями? Это масивы - они были, есть и будут.Задача моя - как и задача этих статей - обучить азам и нюансам работы с движком (а значит неизбежно коснуться и языка, на котором он написан). Объяснить какие-то вещи, общие не для понятия ООП, а конкретные для питона и ренпая. Поднять вопросы, с которыми мне (как человеку, имеющему несколько ЯП в анамнезе) пришлось столкнуться, чтобы остальным было проще. Синтаксис, функциональные возможности, нюансы использования, потенциальные ошибки. Часто я строю эти статьи по принципу "рассказать в одном месте то, что пришлось собирать ошметками по лемме и стэковерфлоу".
Смысл статьи в данном случае - пояснить, чем различаются типы данных, что в каких случаях стоит использовать (почему кортеж, а не словарь, почему список, а не кортеж), и как с ними работать. С этим статья справляется. Больше от нее ничего не требуется. От кодера новелл не требуется, чтобы он умел программировать. Более того, я стараюсь, чтобы эти статьи касались общих принципов программирования в минимально необходимых рамках, потому что, как уже было сказано: программисты поймут, о чем речь, для остальных эта информация будет избыточной.
Примеров кода в статье достаточно.
> И какие нахрен списки? Какие кортежи? Какие распаковки и обмены значениями? Это масивы - они были, есть и будут.
Распаковка и обмен значениями нередко встречается в питоновском и ренпай-коде, поэтому важно было про нее рассказать. Чтобы, столкнувшись с этим явлением, человек сразу понял, что тут происходит и как оно работает, и почему. Если я говорю о типах данных в контексте определенного языка, я стараюсь использовать терминологию, характерную для этого языка. Кортежи и списки - два разных типа данных, о которых говорит и которых различает любая документация питона. Если бы речь тут шла о PHP, то массивом бы называлось все подряд. Вас ведь не возмущает, что я ассоциативный массив со строковыми ключами называю словарем? Если нет, то вы, наверное, шарповик.
Значит Вы недостаточно опытный программист. Потому как языков программирования не существует. Я это еще на первом курсе понял. Объяснять почему - не буду, до этого каждый должен дойти сам. В моем анамнезе их там штук 20, изучение любого "языка программирования" для меня занимает сутки, не более.
Это звучит точно так же, как от человека не требуется чтобы он дышал. Не несите чушь. Невозможно создать что-то, не понимая, как это работает. Пусть на Ренпае упрощенное до невозможности структурное программирование, это не означает, что пейсатель кода не должен понимать, почему он пишет именно так а не иначе. Тем более, СДК рассчитан на, как минимум, уровень n2. Иначе это граната для обезьяны.
Не возмущает. Я не обращаю внимание на такие мелочи - не из параноиков, которые теребонькают на любимый язык и люто бугуртят, когда их обижают незнанием терминологии. Массив - везде массив, я смотрю код.
Ваша первая стадия принятия неизбежного - отрицание. А так же сарказм и лесть. Охохохо, весьма, весьма...
Цель моих комментариев - заставить включить мозг обывателей в работу. Люди не понимают многих вещей и думают, что их унижают, но это отнюдь не так. Поэтому боятся иного подхода к проблеме, отличного от классического, вот как Вы. При этом я не сказал ничего, что показало бы мое "превосходство" - это уже Ваша персональная выдумка.
Непременно, непременно. Тем более, мне есть чем поделиться, особенно по теме геймдева.